PysparkのDataFrameで差分のみを取得する方法
端的に言えば, left_anti で join すれば差分情報のみにすることができます。
目的
今回の目的は まったく同じの列を持つ2つのDataFrameがあり、1つは新しいデータがあり、1つは古いデータがある状態です。 古いデータから 更新があった行 追加された行 のみを抽出した差分のDataFrameを作る事が目的です。
内容
- left_anti join を使い、 new_df (新しいデータ)から old_df (古いデータ)に存在しない行を取得します。
- left_anti は、new_df の中で old_df に存在しない行のみを抽出するので、新規追加された行や変更された行が対象になります。
- 完全一致する行は old_df に存在するので除外される ため、変更行も含まれます。
- キー列を基準にした単純な存在チェックではなく、全カラムを比較 することで、値の変更も考慮します。
left_antiとは
https://spark.apache.org/docs/3.5.3/sql-ref-syntax-qry-select-join.html アンチ結合は、右側と一致しない左側の関係からの値を返します。これは、左アンチ結合とも呼ばれます。
leftを new_df , rightを old_df として、 left_anti join で下記の図のように差分を取得します。
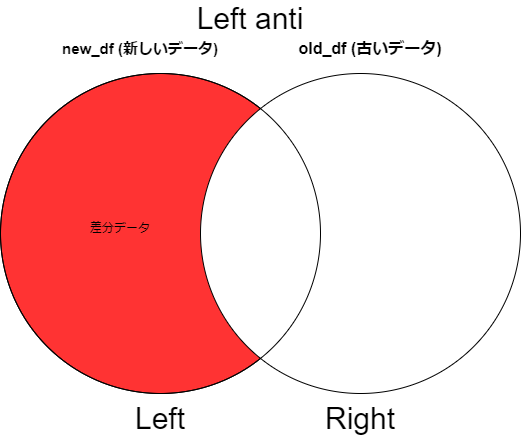
実際のコード
結果
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# 例としてデータを作成
data1 = [
(1, "A", 100, "X"), # 変更なし
(2, "B", 200, "Y"), # 変更なし
(3, "C", 300, "Z") # 変更あり(新データでは col3 が 999 になっている)
]
data2 = [
(1, "A", 100, "X"), # 変更なし
(2, "B", 200, "Y"), # 変更なし
(3, "C", 999, "Z"), # 変更あり
(4, "D", 400, "W") # 新規追加
]
# 古いデータ
old_df = spark.createDataFrame(data1, ["col1", "col2", "col3", "col4"])
# 新しいデータ
new_df = spark.createDataFrame(data2, ["col1", "col2", "col3", "col4"])
# new_df にあって old_df にない(追加 or 変更)行を取得
df3 = new_df.alias("new").join(old_df.alias("old"), on=old_df.columns, how="left_anti")
# 結果表示
df3.show()+----+----+----+----+
|col1|col2|col3|col4|
+----+----+----+----+
| 3| C| 999| Z| # col3 の値が 300 -> 999 に変更された行
| 4| D| 400| W| # 新しく追加された行
+----+----+----+----+
補足: 更新された行のみを取得する場合
もし 更新された行(df1 にはあるが df2 には無い)のみを取得したい場合は、df1 を基準に left_anti を適用します。
df_deleted = df1.alias("old").join(df2.alias("new"), on=df1.columns, how="left_anti")
df_deleted.show()
結果(削除された行)
+----+----+----+----+
|col1|col2|col3|col4|
+----+----+----+----+
| 3| C| 300| Z| # df1にあったがdf2で値が変更された
+----+----+----+----+
コメント